Welcome to the Part 2 of Supervised Machine Learning post. I hope you have gone through the previous posts on Machine Learning and Supervised Learning. If no, kindly go through those before starting from here. In this post we are going to see about the types of supervised learning with examples and their applications.
So let us see a quick recap about Supervised Learning from the last post.
In supervised ML, we train the machine using data which is “labeled.” It means some data is already tagged with the correct answer. The data is labeled and the model learns from the label. So Supervised ML is the process of a model learning from the training labeled dataset.
Types of Supervised Learning
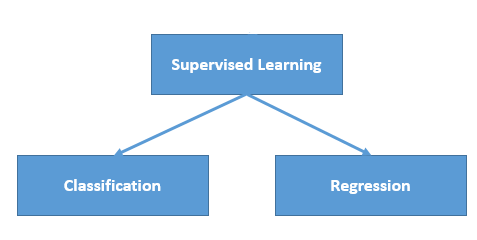
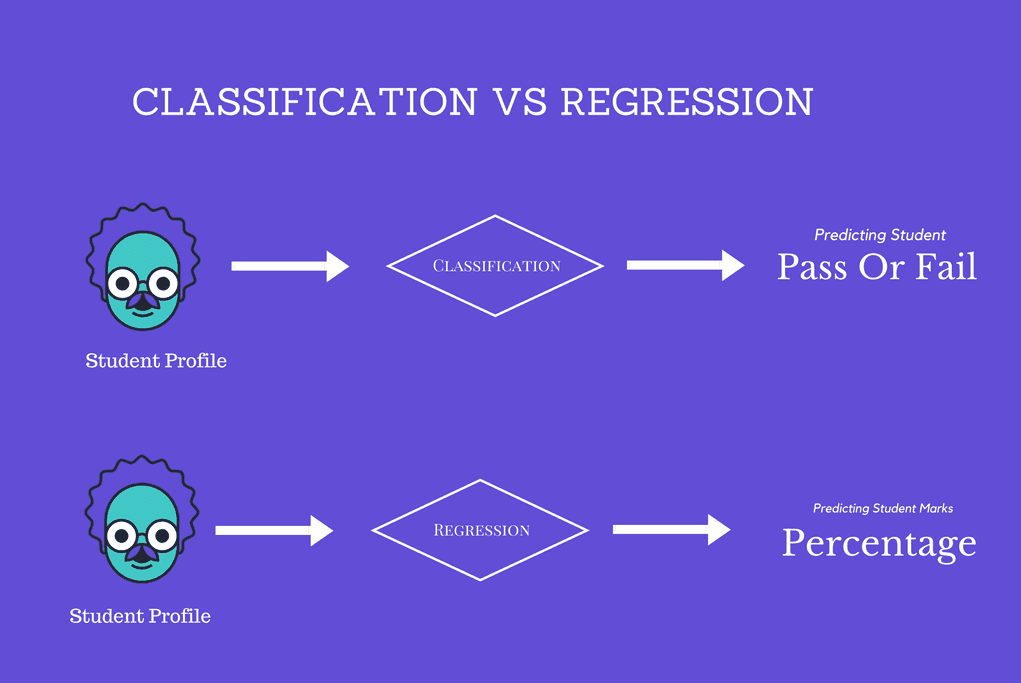
There are only two types of supervised learning techniques. They are Classification and Regression. Every algorithm of supervised Learning. comes under these two types.
Classification
It is used to identify classes to which a new data will fall under which is usually a discrete value. We can classify data under certain labels.
Do you know the difference between discrete data and continuous data?
Discrete data – You can take only specified values. Ex – If you roll a dice, you will get 1,2,3,4,5 or 6. But you will not get 1.5,2.5. Another example – The number of students in a class. We cant have half a student.
Continuous data – You can take any value within a range. Ex – Temperature, Height, Weight. Height of a person can be any value (within the range of human heights) it is not just certain fixed heights.
Discrete data is countable whereas Continuous data is measurable
Understood? So now talking about Classification. Classification should have only discrete value or categorical value.
Examples – Has disease denoted as 1 and Has no disease denoted as 0 is the dependent variable of a supervised Learning which is the labelled data. Similarly, Hacker denoted as 1 and Non hacker denoted as 0 is an example of Classification.
Do you remember the example we discussed in the previous post which is Supervised Learning Part 1. Let us look at it again for better understanding.
Consider an example in which you have to detect the spam mails. The dataset contains some details or variables which has some values for each row. The output variable or the dependent variables consists of only two categories. They are spam and not spam. This is the data which is labeled as spam or not spam. Spam -1 and Not spam – 0.
This data is used to train and test the model. From the training data, the model learns. Then the model is tested with the new or test data to see whether it is identifying the spam and not spam mails correctly. If the accuracy is less, again the model is trained. Once we get high accuracy the model is deployed.
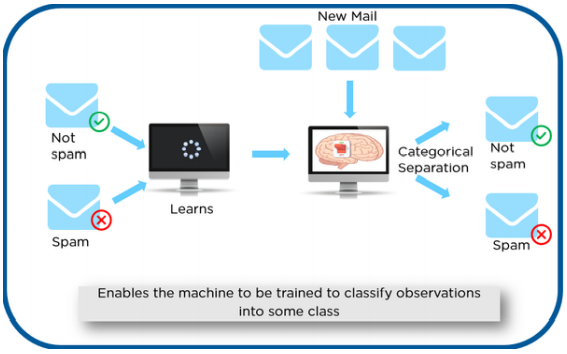
The above discussed example is a Classification type problem of Supervised Learning. There are two types of classifications.
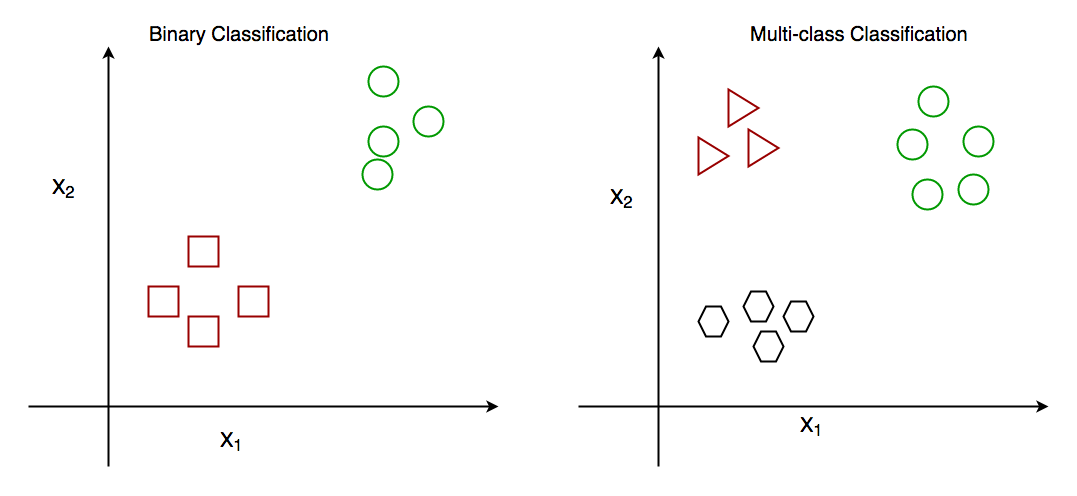
Binomial or Binary Classification
It classifies data only under two classes. This happens in decision trees and in simpler data where there are only two types of data.
Multi-Class Classification
It classifies data under more than two classes. This means there is a lot of data and many possibilities. This happens in random forests.
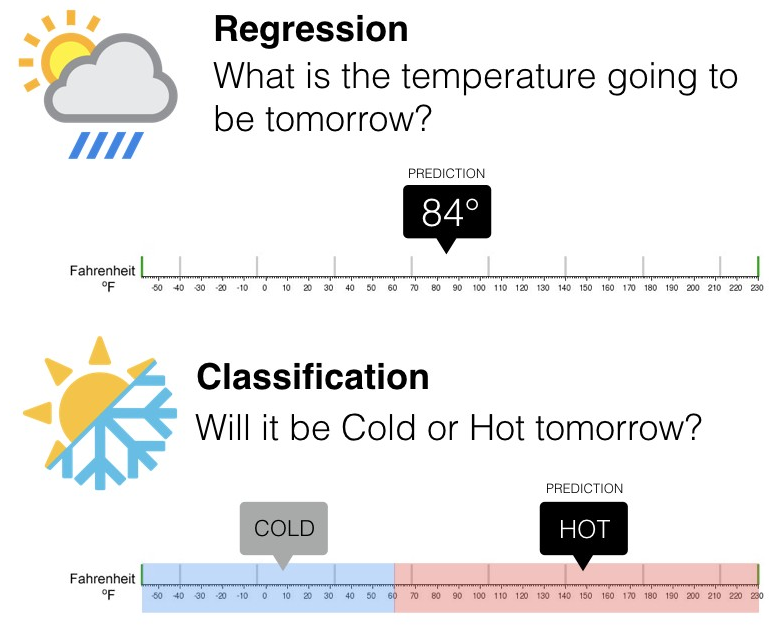
Regression
Classification is about predicting a label but Regression is about predicting a quantity. Regression is the problem of predicting a continuous quantity output. Regression models are used to predict continuous value.
Example – Predicting the price of the house given features like Size, Square feet etc., Regression should have only continuous values.
By now you should know, what is continuous value. If not, go to Classification part in this post again and kindly read it.
For example, you want to train a machine to help you predict how long it will take you to drive home from your workplace. This data includes
- Weather conditions
- Time of the day
- Holidays
All these details are your inputs. The output is the amount of time it took to drive back home on that specific day which is already given in the dataset. That time is the dependent variable which is also the labeled variable.
We know that if it’s raining, then it will take longer time to drive home. But the machine wont understand that and hence it needs data to understand.
The partitioning is done here also as mentioned for the Classification. We have to create a training set. This training set will contain the total commute time and corresponding factors like weather, time, etc. Based on this training set, machine might see there’s a direct relationship between the amount of rain and time you will take to get home.
So it ascertains that the more it rains, the longer you will be driving to get back to your home. Machine may find some of the relationships with your labeled data. This is an example of Regression type of problems in Supervised Learning.
Fact of the day:
Over 3.8 billion people use the internet today, which is 50% of the world’s population. 8 billion devices are connected to the internet. More than 600 new websites are created every minute. There are over 5.8 billion searches per day on Google. Wow😱

https://ipythonquant.wordpress.com/2018/08/05/fooling-around-with-knime-contd-deep-learning/comment-page-1/#comment-15065
LikeLike