PART 1
Welcome to the Supervised Machine Learning post. I hope you have gone through the previous posts on Machine Learning. If no, kindly go through those posts before starting from here. We have seen the various types of ML in the Part 1 of Machine Learning post. So in this post we are going to discuss about Supervised Machine Learning in detail.
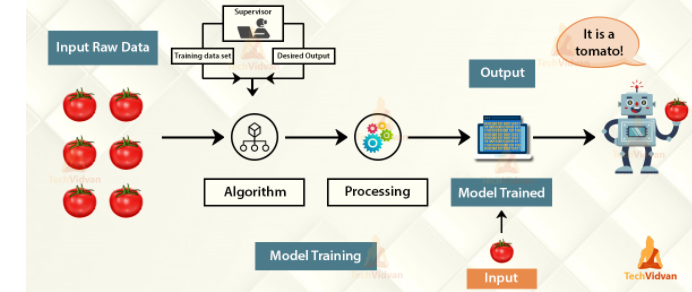
Supervised Machine Learning is a function that maps input of the dataset to an output based on examples such as input-output pairs, providing testing and training to the model.
We train the machine using data which is “labeled.” It means some data is already tagged with the correct answer. The data is labeled and the model learns from the label.
In this learning, we are going to teach the model how to do something. It is the process of an model learning from the training labeled dataset.
In supervised learning, we have dataset and we already know about the correct output, having the idea that there is some relationship between input and output.
How it works?
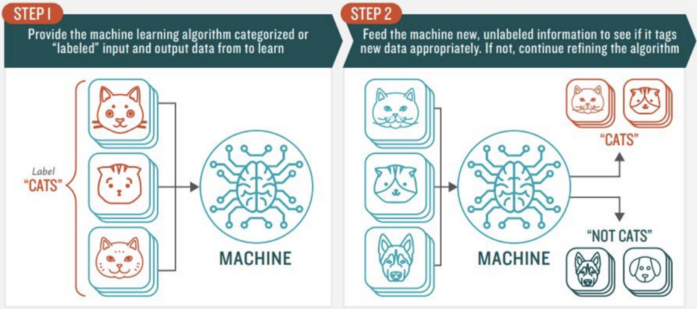
Example
Consider an example in which you have to detect the spam mails. The dataset contains some details or variables which has some values for each row. The output variable or the dependent variables consists of only two categories. They are spam and not spam. This is the data which is labeled as spam or not spam.
This data is used to train and test the model. From the training data, the model learns. Then the model is tested with the new or test data to see whether it is identifying the spam and not spam mails correctly. If the accuracy is less, again the model is trained. Once we get high accuracy the model is deployed.
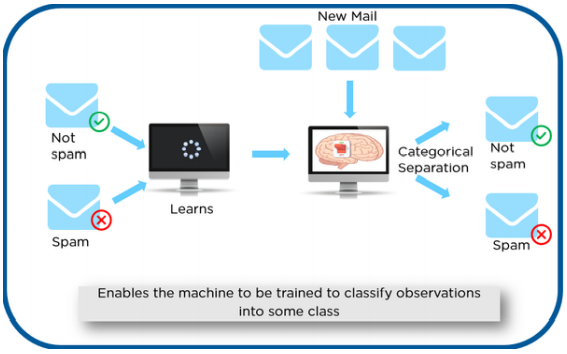
The above given example comes under Classification. Classification is one of the type of supervised learning. We will see about the types of supervised learning in the next post.
Partitioning
Splitting of data into Training and Testing data is known as partitioning. It ensures randomness in the data so that there is no bias in training and testing data. This is done in order to build a model with the training data and test the same model with the remaining data.
Mostly the dataset is broken into one of the three below given partitions. Training – 80% and Testing – 20%, Training – 75% and Testing – 25%, Training – 70% and Testing – 30%.
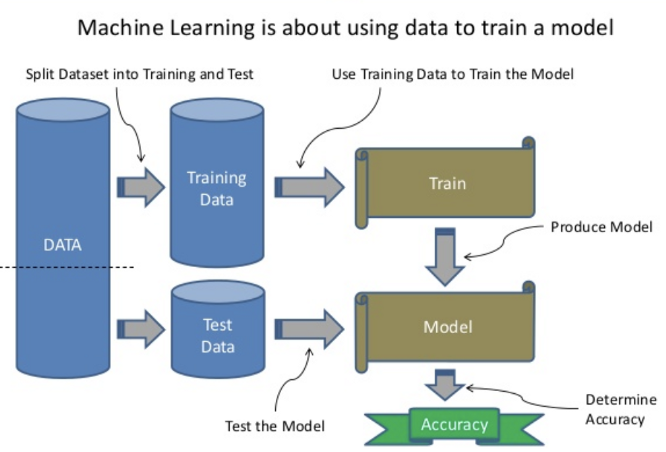
It is important to use the test dataset only once in order to avoid Overfitting.
Overfitting – refers to a model, that models the training data too well. It usually happens when a model learns all the details and noise in the training data. The problem with overfitting is that it negatively impacts the performance of the model on new data.
For some persons, the partitioning concept may differ. For them, Splitting of data into Training, Validation and Testing data is known as partitioning. It allows you to develop highly accurate models that are also relevant to the data that you collect in the future, not just the data the model was trained on.
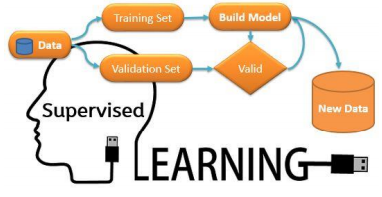
Validation is used to assess the predictive performance of the models and to judge how the model will perform on test data. Validation is used for tuning the parameters of the model whereas Testing is used for performance evaluation.
One of the most used and famous validation technique is k fold cross validation.
Cross Validation
It is used to test the generalizability of the model. As we train any model on the training data, it tends to overfit most times. So cross validation is used to prevent overfitting.
The purpose of using cross-validation is to make you more confident to the model trained on the training set. Without cross-validation, your model may perform pretty well on the training set, but the performance decreases when applied to the testing set.
The testing set is precious and should be only used once, so the solution is to separate one small part of training set as a test of the trained model, which is the validation set. It can still work well even the volume of training set is small.
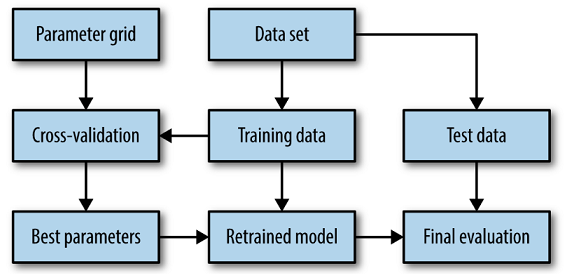
k-fold cross validation
k refers to number of groups that the training data is to be splitted called as folds where 1 fold is retained as test set and the other k-1 folds are used for training the model.
Example – If we set k = 5 (i.e., 5 folds), 4 different subsets of the original training data would be used to train the model and 5th fold would be used for evaluation or testing.
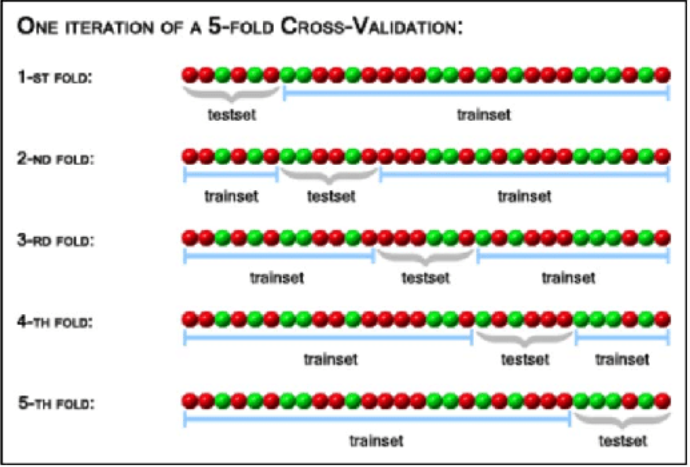
k=5, 4 folds for training and 1 fold for testing purpose and this repeats five times in which each time the test set will differ from the previous one and each data gets the chance to be tested as shown in the above diagram. After 5 iterations, it is possible to calculate the average error rate (and standard deviation) of the model, providing an idea of how well the model is able to generalize.
In the next post we are going to see about the types of supervised learning with examples. Thanks for reading. Do read the further posts on Supervised Learning. Please feel free to connect with me if you have any doubts. Do follow, support, like and subscribe this blog.
Fact of the day:
Butt-shaped robots are used to test phones. What?😲
People often forget their phone is there when they sit down, which can result in a crushed and broken device. That’s why Samsung uses butt-shaped robots to test the durability and bending of the phones.

One thought on “Supervised Learning”