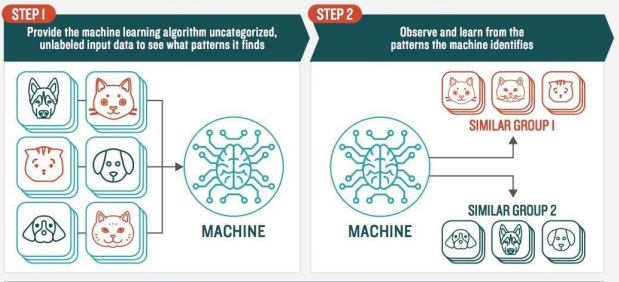
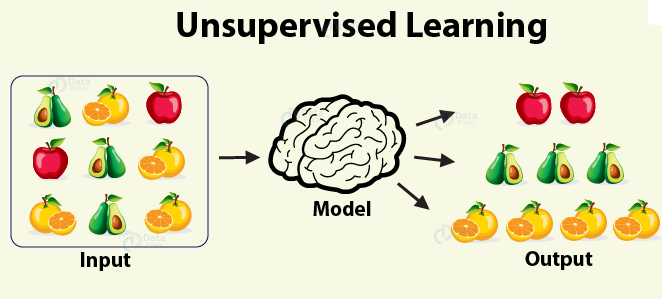
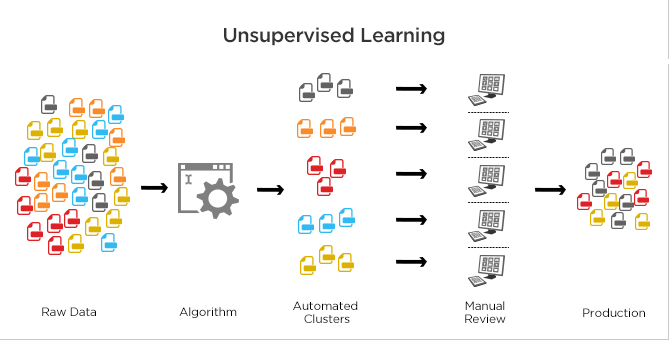
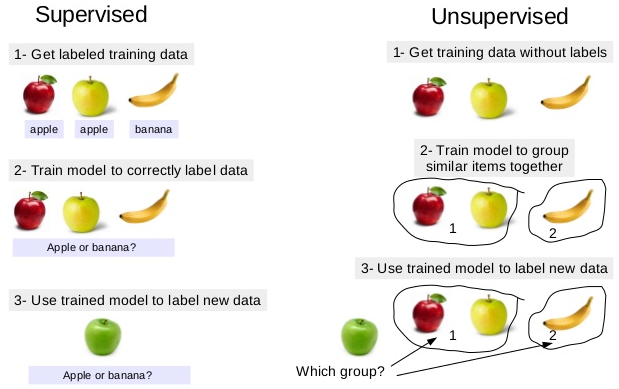
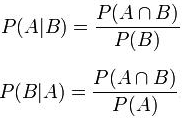Welcome to the Spam Detection using Multinomial Naive Bayes post. I hope you have gone through all the previous posts on Machine Learning, Supervised Learning and Unsupervised Learning.
Spam Detection
Whenever you submit details about your email or contact number on any platform, it has become easy for those platforms to market their products by advertising them by sending emails or by sending messages directly to your contact number.
This results in lots of spam alerts and notifications in your inbox. This is where the task of spam detection comes in. Spam detection means detecting spam messages or emails by understanding text content so that you can only receive notifications about messages or emails that are very important to you.
If spam messages are found, they are automatically transferred to a spam folder and you are never notified of such alerts. This helps to improve the user experience, as many spam alerts can bother many users.
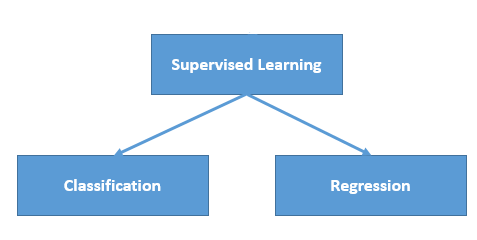
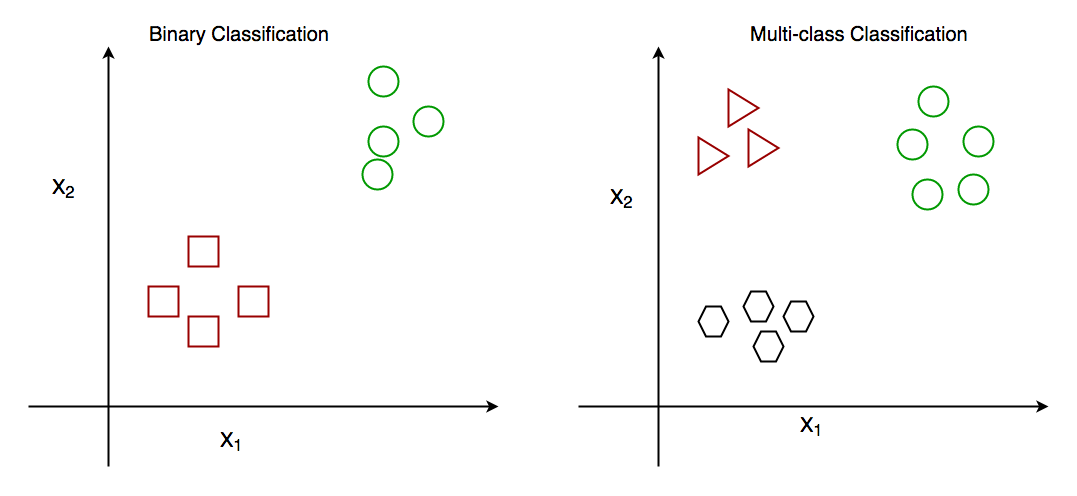
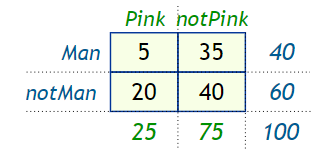
Classification problems can be broadly split into two categories: binary classification problems, and multi-class classification problems. Binary classification means there are only two possible label classes, e.g. a patient’s condition is cancerous or it isn’t, or a financial transaction is fraudulent or it is not.
Multi-class classification refers to cases where there are more than two label classes. An example of this is classifying the sentiment of a movie review into positive, negative, or neutral.
Gmail Spam Detection
We all know the data Google has, is not obviously in paper files. They have data centers which maintain the customers data. Before Google/Gmail decides to segregate the emails into spam or not spam category, before it arrives to your mailbox, hundreds of rules apply to those email in the data centers. These rules describe the properties of a spam email. There are common types of spam filters which are used by Gmail/Google —
Blatant Blocking- Deletes the emails even before it reaches to the inbox.
Bulk Email Filter- This filter helps in filtering the emails that are passed through other categories but are spam.
Category Filters- User can define their own rules which will enable the filtering of the messages according to the specific content or the email addresses etc.
Null Sender Disposition- Dispose of all messages without an SMTP envelope sender address. Remember when you get an email saying, “Not delivered to xyz address”.
Null Sender Header Tag Validation- Validate the messages by checking security digital signature.
There are ways to avoid spam filtering and send your emails straight to the inbox. To learn more about Gmail spam filter please watch this informational video from Google.
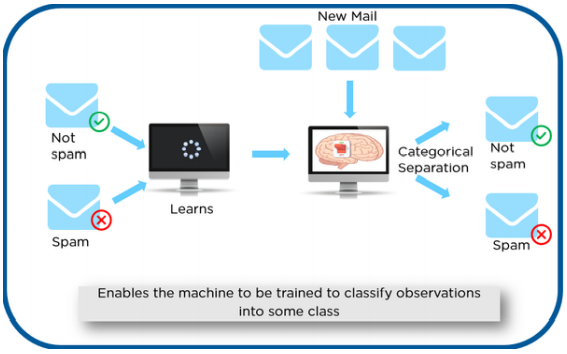
Detecting spam alerts in emails and messages is one of the main applications that every big tech company tries to improve for its customers. Apple’s official messaging app and Google’s Gmail are great examples of such applications where spam detection works well to protect users from spam alerts. So, if you are looking to build a spam detection system, this post is for you.
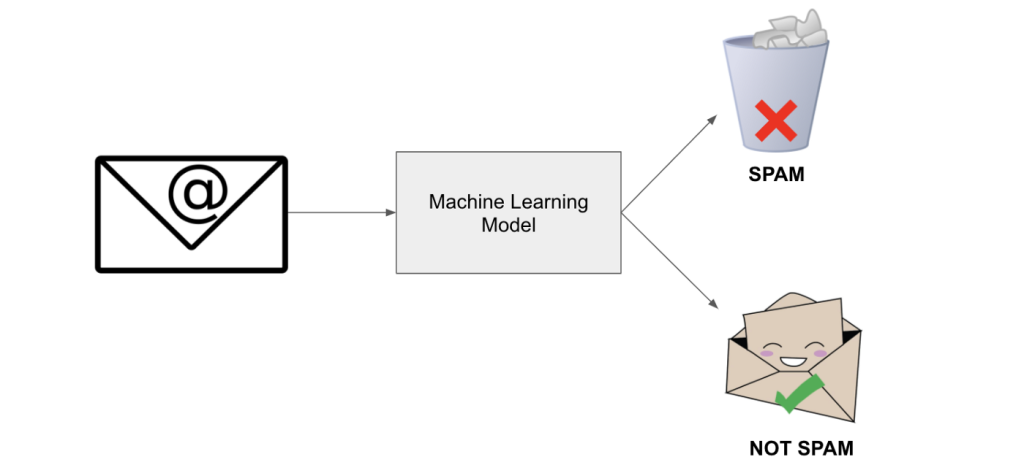
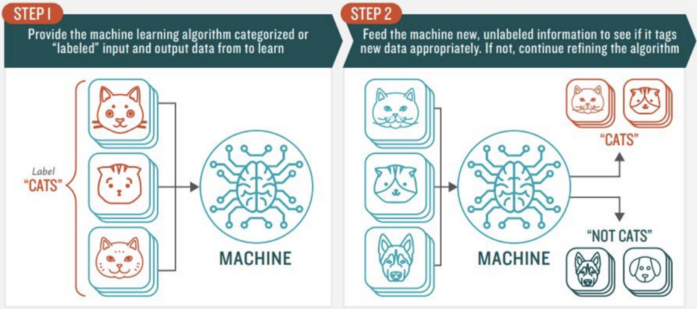
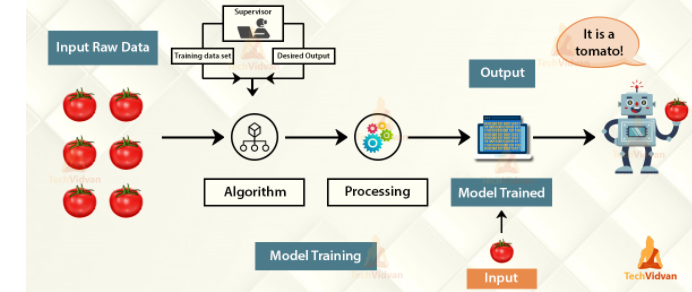
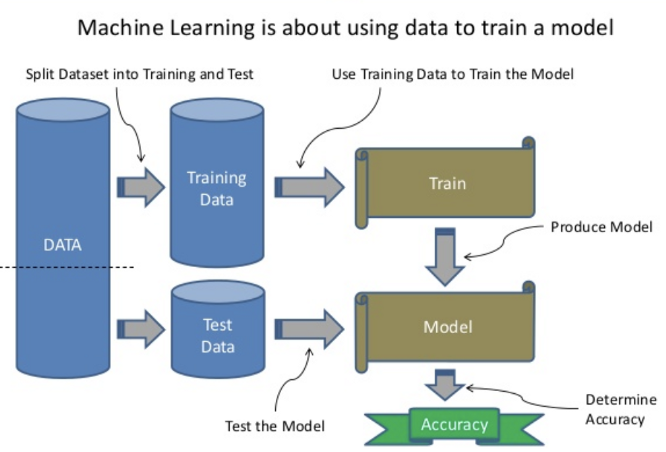
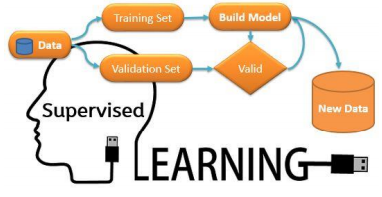
We are hoing to create a Spam Classifier system which distinguishes between Spam and Not Spam mails in the E-mail inbox. For that first we need a dataset which contains some examples of the mails which are spam and not spam. Then based on that data, we have to train the model. After the model is trained, then we have to test the model. After it is done and once we got high accuracy the model can be deployed.
The above given Spam classifier is an example of Supervised Machine Learning. That is just a example of how it works.
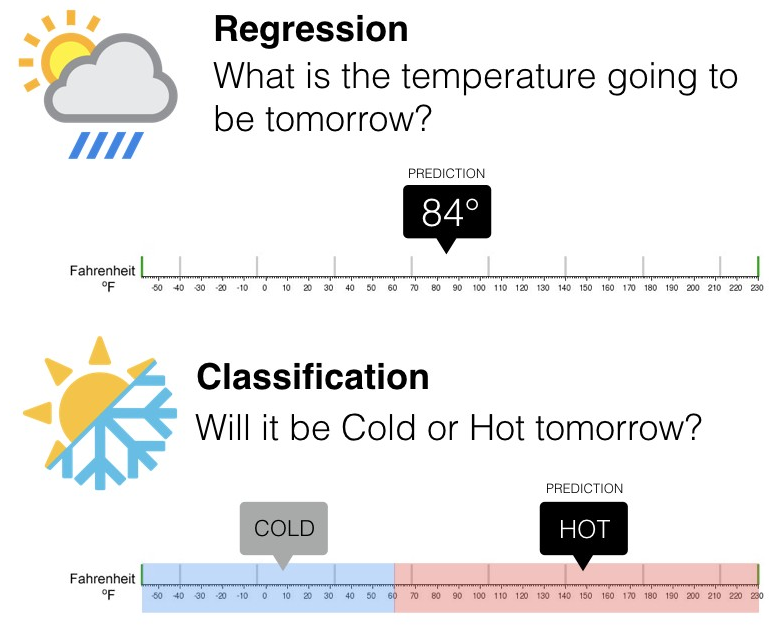
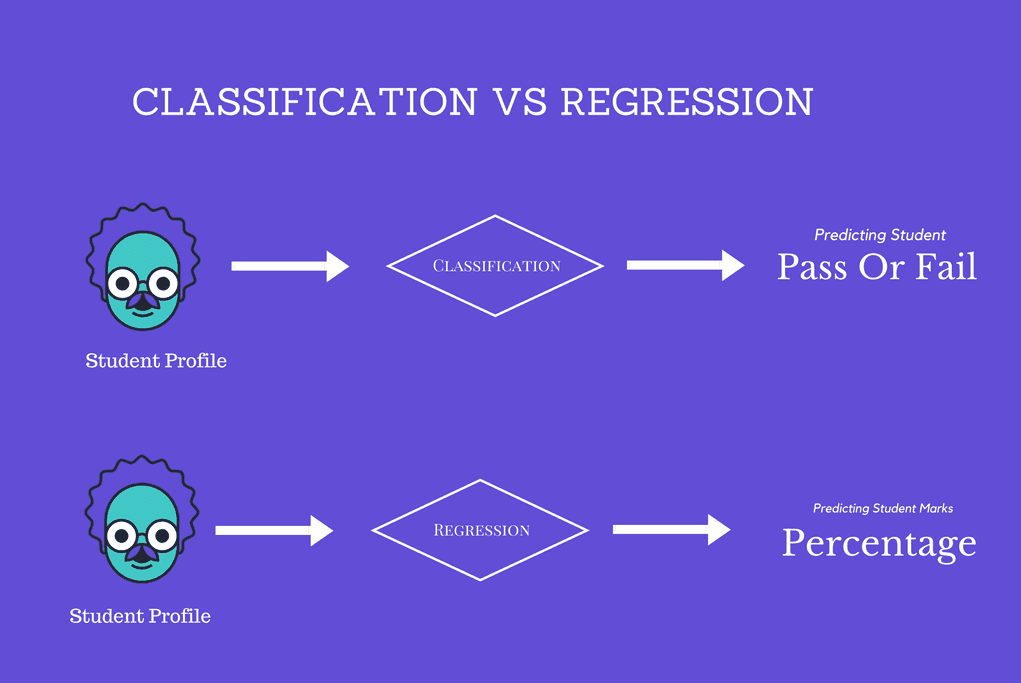
The Classification algorithm is a Supervised Learning technique that is used to identify the category of new observations on the basis of training data. In Classification, a program learns from the given dataset or observations and then classifies new observation into a number of classes or groups.
This application of Spam Detection comes under Classification. So, we are gonna use a Classification algorithm. There are many algorithms for Classification.

For this project, we are gonna use Naive Bayes Algorithm.
What is the Multinomial Naive Bayes?
Multinomial Naive Bayes algorithm is a probabilistic learning method that is mostly used in Natural Language Processing (NLP). The algorithm is based on the Bayes theorem and predicts the tag of a text such as a piece of email or newspaper article. It calculates the probability of each tag for a given sample and then gives the tag with the highest probability as output.
Naive Bayes classifier is a collection of many algorithms where all the algorithms share one common principle, and that is each feature being classified is not related to any other feature. The presence or absence of a feature does not affect the presence or absence of the other feature.
How Multinomial Naive Bayes works?
Naive Bayes is a powerful algorithm that is used for text data analysis and with problems with multiple classes. To understand Naive Bayes theorem’s working, it is important to understand the Bayes theorem concept first as it is based on the latter.
Bayes theorem, formulated by Thomas Bayes, calculates the probability of an event occurring based on the prior knowledge of conditions related to an event. It is based on the following formula:
P(A|B) = P(A) * P(B|A)/P(B)
Where we are calculating the probability of class A when predictor B is already provided.
P(B) = prior probability of B
P(A) = prior probability of class A
P(B|A) = occurrence of predictor B given class A probability
This formula helps in calculating the probability of the tags in the text.
Let us understand the Naive Bayes algorithm with an example. In the below given table, we have taken a data set of weather conditions that is sunny, overcast, and rainy. Now, we need to predict the probability of whether the players will play based on weather conditions.
Training Data Set
| Weather | Sunny | Overcast | Rainy | Sunny | Sunny | Overcast | Rainy | Rainy | Sunny | Rainy | Sunny | Overcast | Overcast | Rainy |
| Play | No | Yes | Yes | Yes | Yes | Yes | No | No | Yes | Yes | No | Yes | Yes | No |
This can be easily calculated by following the below given steps:
Create a frequency table of the training data set given in the above problem statement. List the count of all the weather conditions against the respective weather condition.
| Weather | Yes | No |
| Sunny | 3 | 2 |
| Overcast | 4 | 0 |
| Rainy | 2 | 3 |
| Total | 9 | 5 |
Find the probabilities of each weather condition and create a likelihood table.
| Weather | Yes | No | |
| Sunny | 3 | 2 | =5/14(0.36) |
| Overcast | 4 | 0 | =4/14(0.29) |
| Rainy | 2 | 3 | =5/14(0.36) |
| Total | 9 | 5 | |
| =9/14 (0.64) | =5/14 (0.36) |
Calculate the posterior probability for each weather condition using the Naive Bayes theorem. The weather condition with the highest probability will be the outcome of whether the players are going to play or not.
Use the following equation to calculate the posterior probability of all the weather conditions:
P(A|B) = P(A) * P(B|A)/P(B)
After replacing variables in the above formula, we get:
P(Yes|Sunny) = P(Yes) * P(Sunny|Yes) / P(Sunny)
Take the values from the above likelihood table and put it in the above formula.
P(Sunny|Yes) = 3/9 = 0.33, P(Yes) = 0.64 and P(Sunny) = 0.36
Hence, P(Yes|Sunny) = (0.64*0.33)/0.36 = 0.60
P(No|Sunny) = P(No) * P(Sunny|No) / P(Sunny)
Take the values from the above likelihood table and put it in the above formula.
P(Sunny|No) = 2/5 = 0.40, P(No) = 0.36 and P(Sunny) = 0.36
P(No|Sunny) = (0.36*0.40)/0.36 = 0.6 = 0.40
The probability of playing in sunny weather conditions is higher. Hence, the player will play if the weather is sunny.
Similarly, we can calculate the posterior probability of rainy and overcast conditions, and based on the highest probability; we can predict whether the player will play.
Hope you got an overall understanding about the project – Spam Detection using Multinomial Naive Bayes. This is just the theory part. I have also used Python programming language for this project, coded the project and created a Spam Classifier.
Do check the code in my Github profile and try it from your end. Github Link – https://github.com/muhil17/Spam-Detection-using-Multinomial-Naive-Bayes
Thanks for reading. Do read the further posts. Please feel free to connect with me if you have any doubts. Do follow, support, like and subscribe this blog.